We can use GeneralPodAutoscaler(GPA) to scale the Pod horizontally. GPA is a component developed based on K8s HPA (v2beta2 api).
GPA feature
- It does not depend on the K8s version, it can run on K8s 1.8, 1.9, 1.19 and other versions, only the cluster supports CRD;
- Through GPA’s Provider, more external data sources can be supported, including kafka, redis, etc.;
- Support more scaling modes, with greater flexibility and scalability;
- GPA upgrades are flexible, and there is no need to restart K8s core components during upgrade.
Design
Architecture
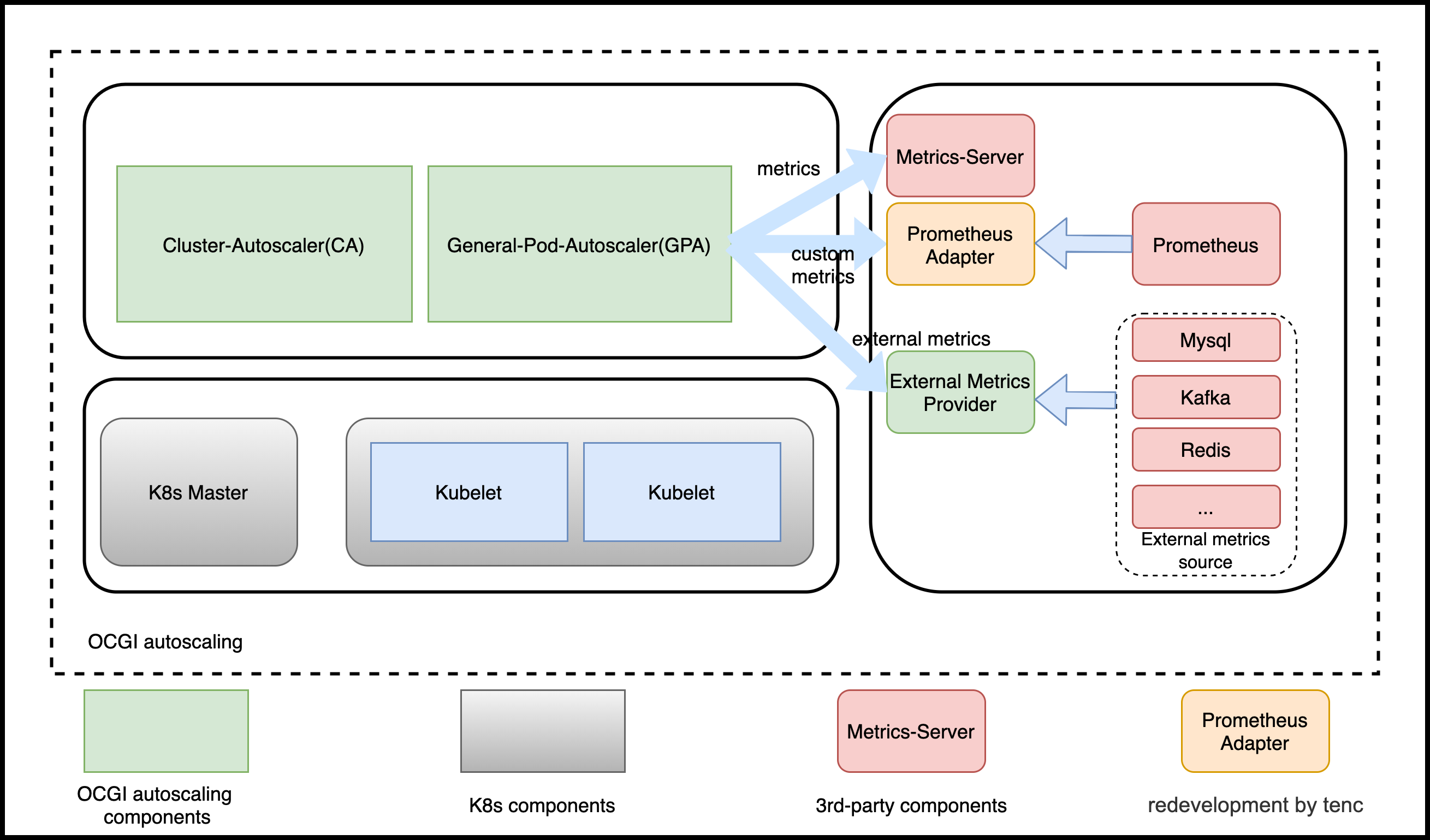
- GPA
Deveoped based on the K8s HPA, and fully compatible with HPA.
- External Metrics Provider
Implement some external metrics Provider, and can scaling based on the external metrics.
Difference between GPA and HPA
This is a example of workload using GPA and HPA.
- HPA
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: test
spec:
maxReplicas: 10
minReplicas: 2
metrics:
- resource:
name: cpu
target:
averageValue: 20
type: AverageValue
type: Resource
scaleTargetRef:
apiVersion: carrier.ocgi.dev/v1alpha1
kind: Squad
name: squad-example1
- GPA
apiVersion: autoscaling.ocgi.dev/v1alpha1
kind: GeneralPodAutoscaler
metadata:
name: test
spec:
maxReplicas: 10
minReplicas: 2
metric: ##difference
metrics:
- resource:
name: cpu
target:
averageValue: 20
type: AverageValue
type: Resource
scaleTargetRef:
apiVersion: carrier.ocgi.dev/v1alpha1
kind: Squad
name: squad-example1
As we can see,
- GPA contains
metricfield in the spec, and themetricsfield is embedded through metric - The spec in HPA yaml directly contains the
metricsfield
In addition, GPA supports more scaling modes, including: event, crontab, webhook.
Spec difference between GPA and HPA
- HPA
// HorizontalPodAutoscalerSpec describes the desired functionality of the HorizontalPodAutoscaler.
type HorizontalPodAutoscalerSpec struct {
// scaleTargetRef points to the target resource to scale, and is used to the pods for which metrics
// should be collected, as well as to actually change the replica count.
ScaleTargetRef CrossVersionObjectReference `json:"scaleTargetRef" protobuf:"bytes,1,opt,name=scaleTargetRef"`
// minReplicas is the lower limit for the number of replicas to which the autoscaler
// can scale down. It defaults to 1 pod. minReplicas is allowed to be 0 if the
// alpha feature gate HPAScaleToZero is enabled and at least one Object or External
// metric is configured. Scaling is active as long as at least one metric value is
// available.
// +optional
MinReplicas *int32 `json:"minReplicas,omitempty" protobuf:"varint,2,opt,name=minReplicas"`
// maxReplicas is the upper limit for the number of replicas to which the autoscaler can scale up.
// It cannot be less that minReplicas.
MaxReplicas int32 `json:"maxReplicas" protobuf:"varint,3,opt,name=maxReplicas"`
// metrics contains the specifications for which to use to calculate the
// desired replica count (the maximum replica count across all metrics will
// be used). The desired replica count is calculated multiplying the
// ratio between the target value and the current value by the current
// number of pods. Ergo, metrics used must decrease as the pod count is
// increased, and vice-versa. See the individual metric source types for
// more information about how each type of metric must respond.
// If not set, the default metric will be set to 80% average CPU utilization.
// +optional
Metrics []MetricSpec `json:"metrics,omitempty" protobuf:"bytes,4,rep,name=metrics"`
// behavior configures the scaling behavior of the target
// in both Up and Down directions (scaleUp and scaleDown fields respectively).
// If not set, the default HPAScalingRules for scale up and scale down are used.
// +optional
Behavior *HorizontalPodAutoscalerBehavior `json:"behavior,omitempty" protobuf:"bytes,5,opt,name=behavior"`
}
- GPA
// GeneralPodAutoscalerSpec describes the desired functionality of the GeneralPodAutoscaler.
type GeneralPodAutoscalerSpec struct {
// DrivenMode is the mode the open autoscaling mode if we do not need scaling according to metrics.
// including MetricMode, TimeMode, EventMode, WebhookMode
// +optional
AutoScalingDrivenMode `json:",inline"`
// scaleTargetRef points to the target resource to scale, and is used to the pods for which metrics
// should be collected, as well as to actually change the replica count.
ScaleTargetRef CrossVersionObjectReference `json:"scaleTargetRef" protobuf:"bytes,1,opt,name=scaleTargetRef"`
// minReplicas is the lower limit for the number of replicas to which the autoscaler
// can scale down. It defaults to 1 pod. minReplicas is allowed to be 0 if the
// alpha feature gate GPAScaleToZero is enabled and at least one Object or External
// metric is configured. Scaling is active as long as at least one metric value is
// available.
// +optional
MinReplicas *int32 `json:"minReplicas,omitempty" protobuf:"varint,2,opt,name=minReplicas"`
// maxReplicas is the upper limit for the number of replicas to which the autoscaler can scale up.
// It cannot be less that minReplicas.
MaxReplicas int32 `json:"maxReplicas" protobuf:"varint,3,opt,name=maxReplicas"`
// behavior configures the scaling behavior of the target
// in both Up and Down directions (scaleUp and scaleDown fields respectively).
// If not set, the default GPAScalingRules for scale up and scale down are used.
// +optional
Behavior *GeneralPodAutoscalerBehavior `json:"behavior,omitempty" protobuf:"bytes,4,opt,name=behavior"`
}
// ExternalAutoScalingDrivenMode defines the mode to trigger auto scaling
type AutoScalingDrivenMode struct {
// MetricMode is the metric driven mode.
// +optional
MetricMode *MetricMode `json:"metric,omitempty" protobuf:"bytes,1,opt,name=metric"`
// Webhook defines webhook mode the allow us to revive requests to scale.
// +optional
WebhookMode *WebhookMode `json:"webhook,omitempty" protobuf:"bytes,2,opt,name=webhook"`
// Time defines the time driven mode, pod would auto scale to max if time reached
// +optional
TimeMode *TimeMode `json:"time,omitempty" protobuf:"bytes,3,opt,name=time"`
// EventMode is the event driven mode
// +optional
EventMode *EventMode `json:"event,omitempty" protobuf:"bytes,4,opt,name=event"`
}
Compared with HPA, GPA supports more modes.
- MetricMode
The usage of this mode is same with K8s HPA.
- WebhookMode
Webhook mode supports application to provide a webhook server, which are called by GPA. Its definition is as follows:
// WebhookMode allow users to provider a server
type WebhookMode struct {
*admregv1b.WebhookClientConfig `json:",inline"`
// Parameters are the webhook parameters
Parameters map[string]string `json:"parameters,omitempty" protobuf:"bytes,1,opt,name=parameters"`
}
- TimeMode
TimeMode supports Crontab mode, which can configure multiple time periods and scale up the workload to a specified number of replicas.
// TimeMode is a mode allows user to define a crontab regular
type TimeMode struct {
// TimeRanges defines a array that for time driven mode
TimeRanges []TimeRange `json:"ranges,omitempty" protobuf:"bytes,1,opt,name=ranges"`
}
// TimeTimeRange is a mode allows user to define a crontab regular
type TimeRange struct {
// Schedule should match crontab format
Schedule string `json:"schedule,omitempty" protobuf:"bytes,1,opt,name=schedule"`
// DesiredReplicas is the desired replicas required by timemode,
DesiredReplicas int32 `json:"desiredReplicas,omitempty" protobuf:"varint,2,opt,name=desiredReplicas"`
}
- EventMode
EventMode supports the use of external data sources including kafka, redis, etc.
// EventMode is the event driven mode
type EventMode struct {
// Triggers are thr event triggers
Triggers []ScaleTriggers `json:"triggers"`
}
// ScaleTriggers reference the scaler that will be used
type ScaleTriggers struct {
// Type are the trigger type
Type string `json:"type"`
// Name is the trigger name
// +optional
Name string `json:"name,omitempty"`
// Metadata contains the trigger config
Metadata map[string]string `json:"metadata"`
}
Questions
How to scale up Squad
Scaling up Squad has the same behavior as other workloads, such as Deployment. GPA will only modify the replicas field of the workload, and the specific behavior is controlled by the corresponding controller.
How to scale down Squad
Squad scaling donw workflow:
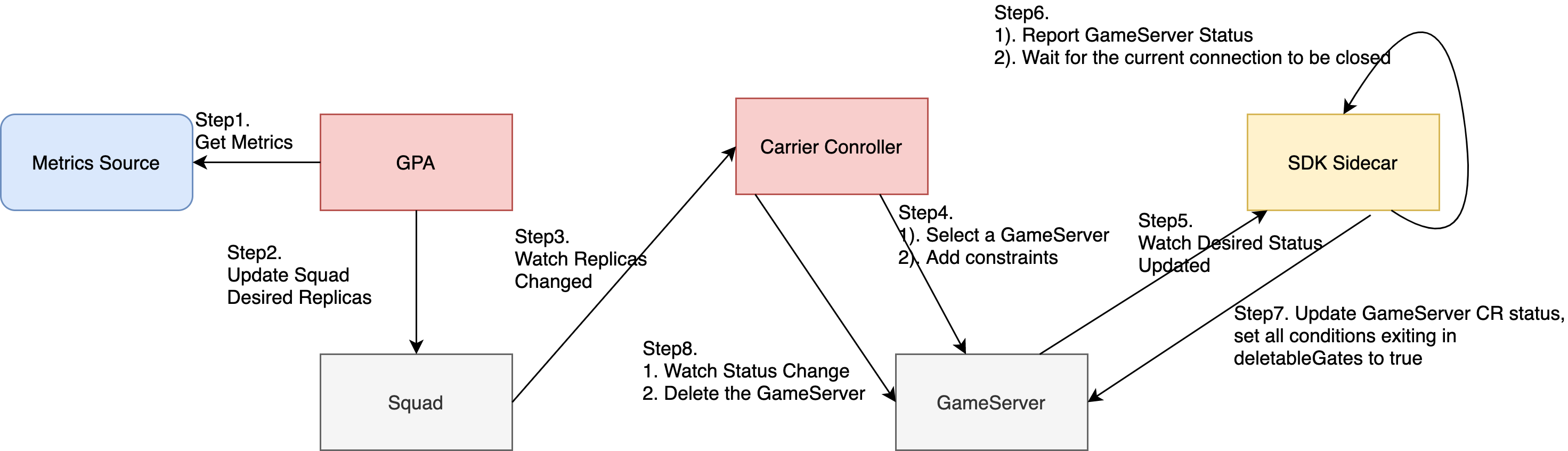
How to define scaling behavior
We can define scaling behavior in Spec:
// GeneralPodAutoscalerBehavior configures the scaling behavior of the target
// in both Up and Down directions (scaleUp and scaleDown fields respectively).
type GeneralPodAutoscalerBehavior struct {
// scaleUp is scaling policy for scaling Up.
// If not set, the default value is the higher of:
// * increase no more than 4 pods per 60 seconds
// * double the number of pods per 60 seconds
// No stabilization is used.
// +optional
ScaleUp *GPAScalingRules `json:"scaleUp,omitempty" protobuf:"bytes,1,opt,name=scaleUp"`
// scaleDown is scaling policy for scaling Down.
// If not set, the default value is to allow to scale down to minReplicas pods, with a
// 300 second stabilization window (i.e., the highest recommendation for
// the last 300sec is used).
// +optional
ScaleDown *GPAScalingRules `json:"scaleDown,omitempty" protobuf:"bytes,2,opt,name=scaleDown"`
}
Exmaples:
- Only scale down one replica in 60 seconds
apiVersion: autoscaling.ocgi.dev/v1alpha1
kind: GeneralPodAutoscaler
metadata:
name: pa-squad-metric
spec:
maxReplicas: 10
minReplicas: 2
metric:
metrics:
- resource:
name: cpu
target:
averageValue: 20
type: AverageValue
type: Resource
scaleTargetRef:
apiVersion: carrier.ocgi.dev/v1alpha1
kind: Squad
name: squad-example1
behavior:
scaleDown:
stabilizationWindowSeconds: 300 ## default 300 for scale down; 0 for scale up
policies:
- type: Pods
value: 1
periodSeconds: 60
selectPolicy: Max # Max, or Min, used when we have multiple policies. Disabled: not scale down.
- Only scale down 10% replicas in 60 seconds
apiVersion: autoscaling.ocgi.dev/v1alpha1
kind: GeneralPodAutoscaler
metadata:
name: pa-squad-metric
spec:
maxReplicas: 10
minReplicas: 2
metric:
metrics:
- resource:
name: cpu
target:
averageValue: 20
type: AverageValue
type: Resource
scaleTargetRef:
apiVersion: carrier.ocgi.dev/v1alpha1
kind: Squad
name: squad-example1
behavior:
scaleDown:
policies:
- type: Percent
value: 10
periodSeconds: 60
The configuration of scaling-up is same with the scaling-down.
The Scaling behavior of GPA is same with the K8s HPA Scaling behavior.