我们通过GeneralPodAutoscaler(GPA)进行Pod水平伸缩。GPA是基于K8s HPA(v2beta2 api)扩展开发的一个组件。
GPA 特点
- 不依赖于K8s版本,可以运行于K8s 1.8、1.9、1.19等版本,只需要集群支持CRD;
- 通过GPA的Provider, 可以支持更多外部数据源,包括kafka, redis等;
- 支持更多伸缩模式,灵活性、扩展性更强;
- GPA升级灵活,升级时不需要重启K8s核心组件。
设计
架构
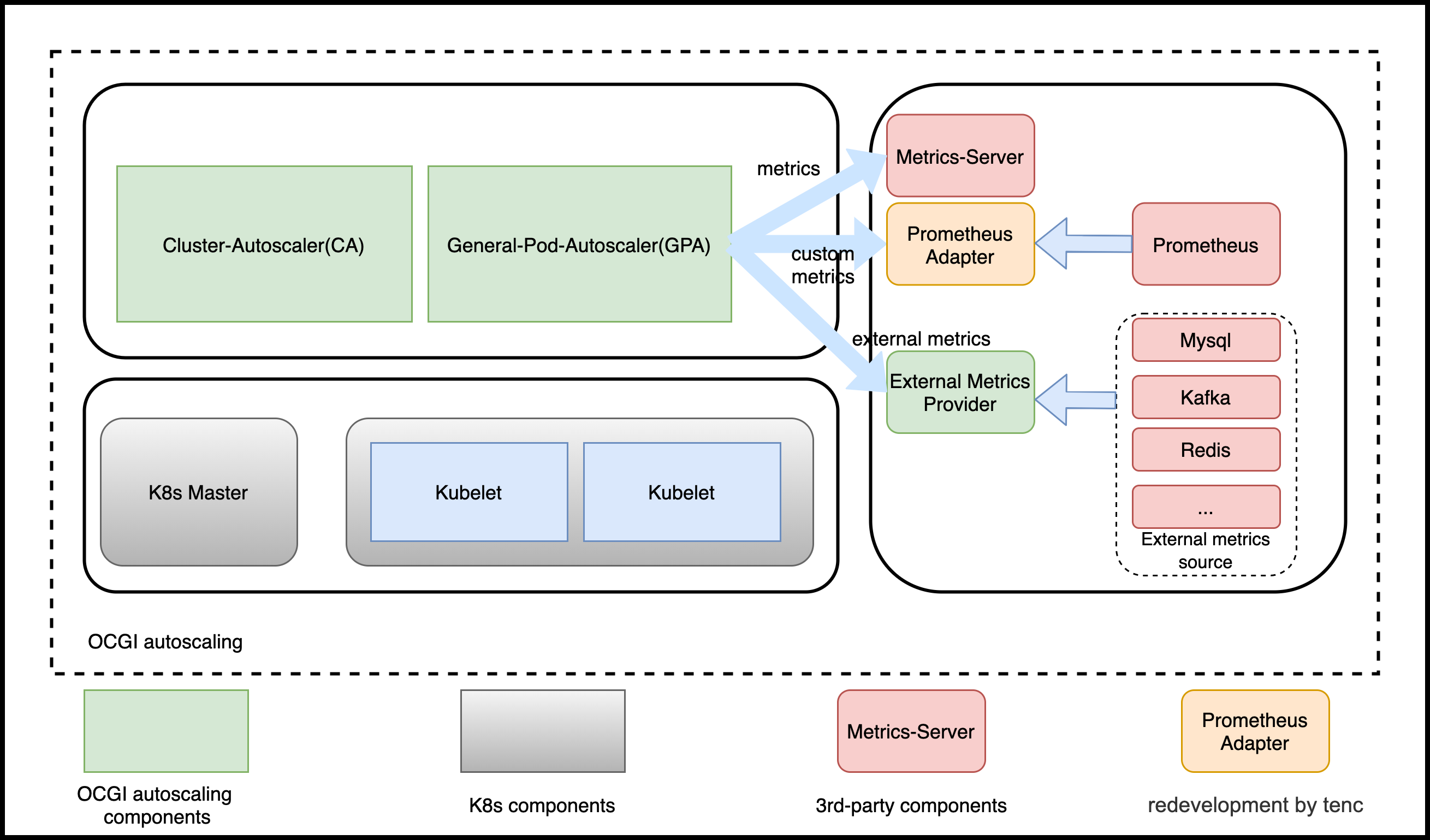
- GPA
基于HPA开发的通用Pod扩缩容组件,覆盖了HPA的所有功能。
- External Metrics Provider
实现了外部资源的Provider, 可以支持自定义外部资源。
GPA和HPA之间的差异
以下内容为例: 一个workload使用HPA和GPA的yaml差异
- HPA
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: test
spec:
maxReplicas: 10
minReplicas: 2
metrics:
- resource:
name: cpu
target:
averageValue: 20
type: AverageValue
type: Resource
scaleTargetRef:
apiVersion: carrier.ocgi.dev/v1alpha1
kind: Squad
name: squad-example1
- GPA
apiVersion: autoscaling.ocgi.dev/v1alpha1
kind: GeneralPodAutoscaler
metadata:
name: test
spec:
maxReplicas: 10
minReplicas: 2
metric: ##difference
metrics:
- resource:
name: cpu
target:
averageValue: 20
type: AverageValue
type: Resource
scaleTargetRef:
apiVersion: carrier.ocgi.dev/v1alpha1
kind: Squad
name: squad-example1
可以看到
GPA的yaml中spec里包含了
metric, 通过metric内嵌了metrics字段HPA的yaml中spec直接包含了
metrics字段'
此外GPA支持更多的伸缩模式,包含:event, crontab, webhook。
GPA和HPA Spec部分差异
- HPA
// HorizontalPodAutoscalerSpec describes the desired functionality of the HorizontalPodAutoscaler.
type HorizontalPodAutoscalerSpec struct {
// scaleTargetRef points to the target resource to scale, and is used to the pods for which metrics
// should be collected, as well as to actually change the replica count.
ScaleTargetRef CrossVersionObjectReference `json:"scaleTargetRef" protobuf:"bytes,1,opt,name=scaleTargetRef"`
// minReplicas is the lower limit for the number of replicas to which the autoscaler
// can scale down. It defaults to 1 pod. minReplicas is allowed to be 0 if the
// alpha feature gate HPAScaleToZero is enabled and at least one Object or External
// metric is configured. Scaling is active as long as at least one metric value is
// available.
// +optional
MinReplicas *int32 `json:"minReplicas,omitempty" protobuf:"varint,2,opt,name=minReplicas"`
// maxReplicas is the upper limit for the number of replicas to which the autoscaler can scale up.
// It cannot be less that minReplicas.
MaxReplicas int32 `json:"maxReplicas" protobuf:"varint,3,opt,name=maxReplicas"`
// metrics contains the specifications for which to use to calculate the
// desired replica count (the maximum replica count across all metrics will
// be used). The desired replica count is calculated multiplying the
// ratio between the target value and the current value by the current
// number of pods. Ergo, metrics used must decrease as the pod count is
// increased, and vice-versa. See the individual metric source types for
// more information about how each type of metric must respond.
// If not set, the default metric will be set to 80% average CPU utilization.
// +optional
Metrics []MetricSpec `json:"metrics,omitempty" protobuf:"bytes,4,rep,name=metrics"`
// behavior configures the scaling behavior of the target
// in both Up and Down directions (scaleUp and scaleDown fields respectively).
// If not set, the default HPAScalingRules for scale up and scale down are used.
// +optional
Behavior *HorizontalPodAutoscalerBehavior `json:"behavior,omitempty" protobuf:"bytes,5,opt,name=behavior"`
}
- GPA
// GeneralPodAutoscalerSpec describes the desired functionality of the GeneralPodAutoscaler.
type GeneralPodAutoscalerSpec struct {
// DrivenMode is the mode the open autoscaling mode if we do not need scaling according to metrics.
// including MetricMode, TimeMode, EventMode, WebhookMode
// +optional
AutoScalingDrivenMode `json:",inline"`
// scaleTargetRef points to the target resource to scale, and is used to the pods for which metrics
// should be collected, as well as to actually change the replica count.
ScaleTargetRef CrossVersionObjectReference `json:"scaleTargetRef" protobuf:"bytes,1,opt,name=scaleTargetRef"`
// minReplicas is the lower limit for the number of replicas to which the autoscaler
// can scale down. It defaults to 1 pod. minReplicas is allowed to be 0 if the
// alpha feature gate GPAScaleToZero is enabled and at least one Object or External
// metric is configured. Scaling is active as long as at least one metric value is
// available.
// +optional
MinReplicas *int32 `json:"minReplicas,omitempty" protobuf:"varint,2,opt,name=minReplicas"`
// maxReplicas is the upper limit for the number of replicas to which the autoscaler can scale up.
// It cannot be less that minReplicas.
MaxReplicas int32 `json:"maxReplicas" protobuf:"varint,3,opt,name=maxReplicas"`
// behavior configures the scaling behavior of the target
// in both Up and Down directions (scaleUp and scaleDown fields respectively).
// If not set, the default GPAScalingRules for scale up and scale down are used.
// +optional
Behavior *GeneralPodAutoscalerBehavior `json:"behavior,omitempty" protobuf:"bytes,4,opt,name=behavior"`
}
// ExternalAutoScalingDrivenMode defines the mode to trigger auto scaling
type AutoScalingDrivenMode struct {
// MetricMode is the metric driven mode.
// +optional
MetricMode *MetricMode `json:"metric,omitempty" protobuf:"bytes,1,opt,name=metric"`
// Webhook defines webhook mode the allow us to revive requests to scale.
// +optional
WebhookMode *WebhookMode `json:"webhook,omitempty" protobuf:"bytes,2,opt,name=webhook"`
// Time defines the time driven mode, pod would auto scale to max if time reached
// +optional
TimeMode *TimeMode `json:"time,omitempty" protobuf:"bytes,3,opt,name=time"`
// EventMode is the event driven mode
// +optional
EventMode *EventMode `json:"event,omitempty" protobuf:"bytes,4,opt,name=event"`
}
GPA支持更多的模式。
- MetricMode
该模式和原生HPA 使用metric的方式一致。
- WebhookMode
Webhook模式支持用户提供一个webhook server、相关的接口,由GPA进行调用。其定义如下:
// WebhookMode allow users to provider a server
type WebhookMode struct {
*admregv1b.WebhookClientConfig `json:",inline"`
// Parameters are the webhook parameters
Parameters map[string]string `json:"parameters,omitempty" protobuf:"bytes,1,opt,name=parameters"`
}
- TimeMode
TimeMode支持Crontab的模式,可以配置多个时间段,扩容到指定数量。
// TimeMode is a mode allows user to define a crontab regular
type TimeMode struct {
// TimeRanges defines a array that for time driven mode
TimeRanges []TimeRange `json:"ranges,omitempty" protobuf:"bytes,1,opt,name=ranges"`
}
// TimeTimeRange is a mode allows user to define a crontab regular
type TimeRange struct {
// Schedule should match crontab format
Schedule string `json:"schedule,omitempty" protobuf:"bytes,1,opt,name=schedule"`
// DesiredReplicas is the desired replicas required by timemode,
DesiredReplicas int32 `json:"desiredReplicas,omitempty" protobuf:"varint,2,opt,name=desiredReplicas"`
}
- EventMode
EventMode支持使用外部数据源包括kafka, redis等.
// EventMode is the event driven mode
type EventMode struct {
// Triggers are thr event triggers
Triggers []ScaleTriggers `json:"triggers"`
}
// ScaleTriggers reference the scaler that will be used
type ScaleTriggers struct {
// Type are the trigger type
Type string `json:"type"`
// Name is the trigger name
// +optional
Name string `json:"name,omitempty"`
// Metadata contains the trigger config
Metadata map[string]string `json:"metadata"`
}
问题
如何实现扩容GameServer
扩容GameServer和其余workload, 如:deployment等行为一致,GPA只会修改workload的replicas字段,具体的行为用对应controller控制。
如何实现缩容GameServer
GameServer缩容流程:
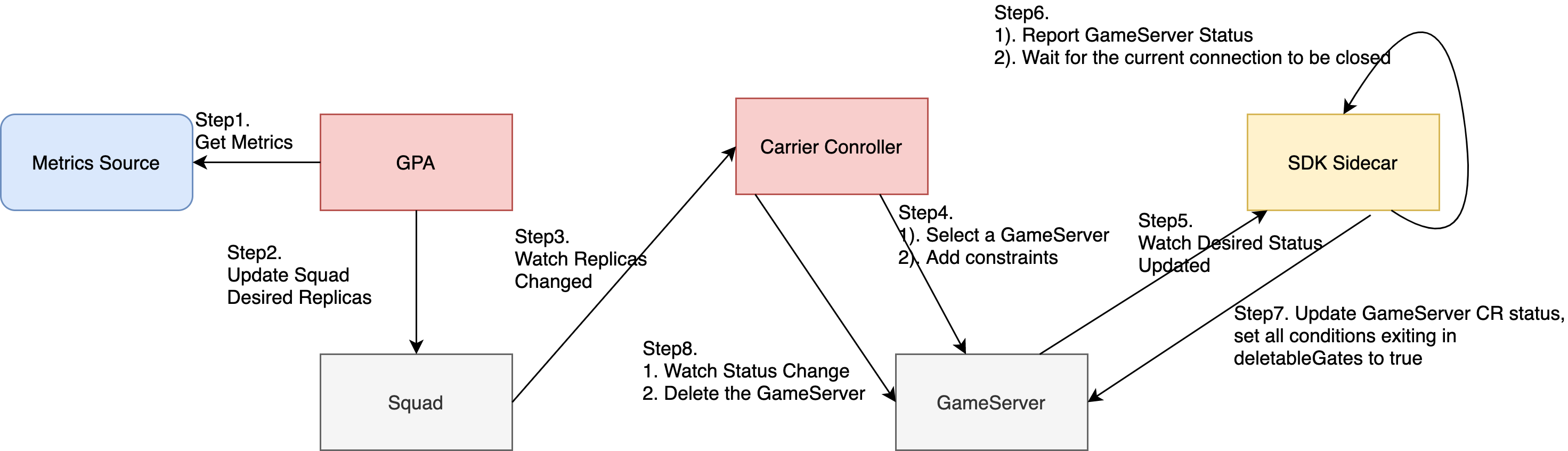
怎么控制扩/缩容的具体行为
可以下spec中定义:
// GeneralPodAutoscalerBehavior configures the scaling behavior of the target
// in both Up and Down directions (scaleUp and scaleDown fields respectively).
type GeneralPodAutoscalerBehavior struct {
// scaleUp is scaling policy for scaling Up.
// If not set, the default value is the higher of:
// * increase no more than 4 pods per 60 seconds
// * double the number of pods per 60 seconds
// No stabilization is used.
// +optional
ScaleUp *GPAScalingRules `json:"scaleUp,omitempty" protobuf:"bytes,1,opt,name=scaleUp"`
// scaleDown is scaling policy for scaling Down.
// If not set, the default value is to allow to scale down to minReplicas pods, with a
// 300 second stabilization window (i.e., the highest recommendation for
// the last 300sec is used).
// +optional
ScaleDown *GPAScalingRules `json:"scaleDown,omitempty" protobuf:"bytes,2,opt,name=scaleDown"`
}
示例
- 60秒内缩容只缩容1个副本
apiVersion: autoscaling.ocgi.dev/v1alpha1
kind: GeneralPodAutoscaler
metadata:
name: pa-squad-metric
spec:
maxReplicas: 10
minReplicas: 2
metric:
metrics:
- resource:
name: cpu
target:
averageValue: 20
type: AverageValue
type: Resource
scaleTargetRef:
apiVersion: carrier.ocgi.dev/v1alpha1
kind: Squad
name: squad-example1
behavior:
scaleDown:
stabilizationWindowSeconds: 300 ## default 300 for scale down; 0 for scale up
policies:
- type: Pods
value: 1
periodSeconds: 60
selectPolicy: Max # Max, or Min, used when we have multiple policies. Disabled: not scale down.
- 60秒内只缩容10%的副本
apiVersion: autoscaling.ocgi.dev/v1alpha1
kind: GeneralPodAutoscaler
metadata:
name: pa-squad-metric
spec:
maxReplicas: 10
minReplicas: 2
metric:
metrics:
- resource:
name: cpu
target:
averageValue: 20
type: AverageValue
type: Resource
scaleTargetRef:
apiVersion: carrier.ocgi.dev/v1alpha1
kind: Squad
name: squad-example1
behavior:
scaleDown:
policies:
- type: Percent
value: 10
periodSeconds: 60
扩容的相关配置和缩容一致。
GPA的Scaling behavior配置与K8s HPA Scaling behavior保持一致。